

Przy okazji wiadomości, komunikatów i materiałów nawiązujących w jakiś sposób do sztucznej inteligencji, często pojawia się pojęcie sztucznych sieci neuronowych. Dowiadujemy się, że system zrealizowano przy pomocy sieci neuronowej, albo, że sieć neuronowa wspomaga działanie jakiegoś urządzenia. Tylko co kryje się za tym pojęciem? Czym są sztuczne sieci neuronowe?
Na początek mały disclaimer – materiał ten będzie operował na uproszczeniach. Przy temacie tak złożonym, jak sztuczne sieci neuronowe, niewystarczająca do pełnego opisu jest nawet pokaźnych rozmiarów książka. Postaram się jednak przybliżyć niektóre z aspektów i odpowiedzieć na najczęściej zadawane pytania. Co sprawia, że stały się one tak popularne? Gdzie znajdują swoje zastosowanie? Jaka magia stoi za tym, że możemy komputer uczyć, zamiast go programować? I wreszcie – jak powstały?
Poznając budowę mózgu
Odpowiedzi na to ostatnie pytanie należy szukać w neurobiologii. Obserwacje ludzi okaleczonych podczas wojen czy wypadków pozwoliły naukowcom zauważyć, że różne części mózgu odpowiedzialne są za różne procesy. Lewa półkula odpowiada za sterowanie prawą ręką, a prawa obsługuje rękę lewą. Lewa półkula kontroluje myślenie ścisłe, analityczne, prawa natomiast daje nam zdolności artystyczne, wyobraźnię przestrzenną oraz zdolność do myślenia abstrakcyjnego. Pomimo tych podziałów jednocześnie wykorzystywane są obie półkule.
Wynika to z faktu, iż półkule nie są jakimś tworem jednostkowym, ale składają się z komórek nerwowych, czyli neuronów. Obecnie szacuje się, że na sam mózg składa się sieć stworzona ze 100 miliardów neuronów, przy czym warto wiedzieć, że neurony obecne są w całym układzie nerwowym, nie tylko w mózgu. Pojedynczy neuron to prosty twór, który zdolny jest do przetwarzania i przewodzenia sygnału elektrycznego; składa się z ciała komórki, wypustek zwanych dendrytami, którymi sygnał dociera do neuronu, oraz jednej wypustki zwanej aksonem, która przesyła sygnał dalej. Akson z kolei rozgałęzia się na synapsy, które prowadzą do kolejnych neuronów.
Schemat działania również jest prosty – pojedynczy neuron odbiera sygnał od ogromnej liczby innych neuronów (dochodzącej nawet do tysiąca), a następnie sumuje impulsy pobudzające i hamujące; w zależności od wyniku, sygnał (ten sam, ponieważ jest tylko jeden akson) może być przesłany do kolejnych neuronów (za pomocą rozgałęziających się synaps). I to wszystko.
Nie dajcie się jednak zwieść pozornej prostocie; przypominam, że w ważącym niecałe półtora kilograma mózgu znajduje się sieć złożona ze stu miliardów połączonych w przeróżny sposób neuronów. Również samo przesyłanie sygnałów regulowane jest skomplikowanymi chemiczno-elektrycznymi procesami. Nie będę się jednak w ten temat zagłębiał, ponieważ czas wrócić do sztucznych sieci neuronowych; wprowadzenie miało jedynie na celu ułatwienie zrozumienia idei za nimi stojącej.

Czy można stworzyć sztuczny neuron?
Naturalnym następstwem poznania biologicznej budowy mózgu stało się pytanie: czy możliwe jest odwzorowanie mechanizmu jego działania za pomocą sztucznych neuronów? Technicznie rzecz biorąc, pojedynczy neuron jest w swej budowie i działaniu bardzo prosty, wyzwaniem natomiast staje się sprawienie, by w praktycznym zastosowaniu odtworzyć całą sieć takich neuronów.
Ciekawostką jest, że pierwsza sztuczna sieć neuronowa nie została zaprogramowana, lecz zbudowana; w 1957 roku Frank Rosenblatt i Charles Wightman stworzyli elektromechaniczne urządzenie nazwane Perceptronem, które potrafiło rozpoznać znaki alfanumeryczne. Rodzaj sygnału przesyłanego synapsami (wzmacniający lub osłabiający) regulowano prostymi potencjometrami obracanymi za pomocą silników elektrycznych. Na całość składało się 8 komórek nerwowych oraz 512 połączeń. I choć działanie tego mechanizmu pozostawiało wiele do życzenia, to jednak jest to przykład pierwszej praktycznie działającej sztucznej realizacji sieci nerwowej.
Patriotycznie warto również wspomnieć, że genialny inżynier Jacek Karpiński, wraz ze swoim pomocnikiem profesorem Ryszardem Michalskim, zbudowali polski perceptron. Sieć neuronowa oparta na dwóch tysiącach tranzystorów pozwoliła na pracę maszyny, która badała otoczenie za pomocą kamery i uczyła się rozpoznawania nieznanych jej kształtów. Było to drugie tego typu urządzenie na świecie.


Struktura sztucznej sieci neuronowej
Przenieśmy się do nieco bliższej przeszłości, kiedy sztuczne sieci neuronowe doczekały się realizacji w postaci programów, która, nie ukrywajmy, jest znacznie prostsza niż urządzenie elektromechaniczne. Znacznie łatwiej jest nie tylko zaprogramować działanie pojedynczego neuronu, ale także skalować sieć i elastycznie modyfikować jej strukturę. No właśnie, strukturę; generalnie możemy wyróżnić dwa typy sieci – sieci jednokierunkowe (gdzie sygnał leci od wejścia do wyjścia) oraz sieci ze sprzężeniem zwrotnym (gdzie sygnał wyjściowy jest jednocześnie sygnałem wejściowym). Poniższa grafika przedstawia przykład sieci tego pierwszego typu.
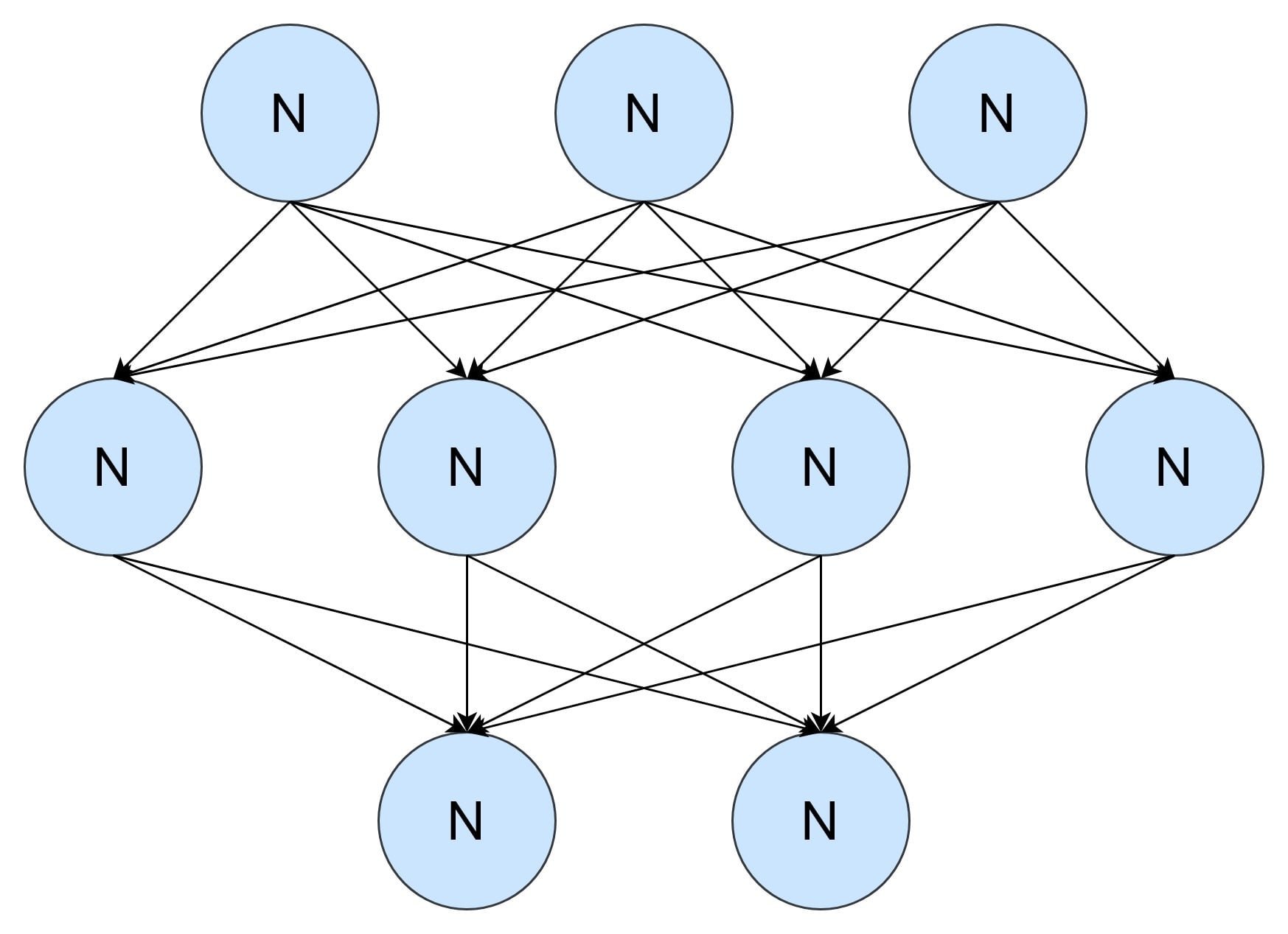

W każdej sieci neurony zgrupowane są w warstwach; ogółem możemy wyróżnić warstwę wejściową i warstwę wyjściową (obowiązkowe), a także znajdujące się pomiędzy nimi warstwy ukryte (opcjonalne). Połączenia występują pomiędzy neuronami dwóch sąsiednich warstw, natomiast nie ma ich pomiędzy neuronami w obrębie jednej warstwy. Każde połączenie opisane jest parametrem wagi, czyli wartości liczbowej, która modyfikowana jest w trakcie uczenia. Waga pozwala w uproszczony sposób zasymulować to, czy sygnał ma być wzmacniający, czy wygłuszający.
Jak możecie zauważyć, sztuczna struktura odwzorowuje tę występującą w biologii. Do pojedynczego neuronu wchodzi kilka różnych wejść (dendrytów); przesyłany wejściem sygnał jest następnie przetwarzany w środku (w ciele komórki), by w efekcie uzyskać sygnał wyjściowy, który przesyłany jest do neuronów w kolejnej warstwie (synapsami wychodzącymi z jednego aksonu). Wartość na wyjściu neuronu jest taka sama dla każdego połączenia, natomiast każde połączenie opisane jest inną wartością wagi. Szczegółów działań matematycznych nie będę tutaj przedstawiał; zainteresowanych odsyłam do literatury przytoczonej w źródłach na dole materiału.

Uczenie zamiast programowania
Jak wspominałem w poprzednich odcinkach tego cyklu, siłą sztucznej inteligencji jest fakt, iż nie jest ona programowana, tylko uczona. Zadaniem programistów jest jedynie zaprogramowanie struktury sieci oraz metody jej uczenia, natomiast to, co z tego uczenia wyjdzie, zależy w głównej mierze od danych wejściowych, którymi chcemy naszą sieć nauczyć. Metod uczenia jest całe mnóstwo, możemy je zaś podzielić na dwa typy – uczenie nadzorowane oraz uczenie bez nadzoru. To pierwsze wymaga podania oczekiwanej wartości wyjściowej (czyli wyjścia neuronów w ostatniej warstwie) i pozwala wytrenować sieć w pożądanym przez nas kierunku. Z kolei uczenie nienadzorowane pozwala sieci wypracować własny sposób przetwarzania danych, na przykład poprzez odnajdywanie podobieństw albo wykrycia regularności. Tym samym efekty uczenia nienadzorowanego mogą być ciekawe i zaskakujące.
Uczenie jest procesem modyfikowania wag połączeń pomiędzy neuronami. Tak, jak w naszym mózgu uczenie powoduje tworzenie nowych połączeń pomiędzy neuronami, tak w sztucznych sieciach neuronowych zostało to odwzorowane właśnie za pomocą wag połączeń. Mówiąc bardziej po ludzku – waga określa istotność danego połączenia. Sposób jej modyfikowania zależny jest już od konkretnej metody uczenia, natomiast, ponownie jak wyżej, po więcej szczegółów odsyłam do literatury.
To, co chcemy w procesie uczenia uzyskać, to zestaw wag, który pozwoli jak najdokładniej realizować nasz cel. Trenujemy sieć w kierunku określonego przez nas klasyfikowania obiektów? Musimy przedstawić jej odpowiednią ilość danych uczących i powiedzieć, jak ma je klasyfikować, a sieć po nauczeniu będzie w stanie wiedzę uogólniać. Chcemy, by sieć sama ustaliła, w jaki sposób klasyfikować dane? Wrzucamy dane uczące i obserwujemy, co się dzieje. W każdym przypadku losowo wygenerowany zestaw wag modyfikowany jest zgodnie z założeniami metody uczenia. I choć może się to wydawać abstrakcyjne (bo też takie jest), to jednak sztuczne sieci neuronowe… po prostu działają.

Wiedza z ubiegłego wieku
Możecie wierzyć lub nie, ale opisywana powyżej wiedza nie jest niczym nowym; podstawy sztucznych sieci neuronowych mają już kilkadziesiąt lat; jedna z najpopularniejszych (i najskuteczniejszych) metod uczenia nadzorowanego po raz pierwszy została sformułowana już w 1974 roku przez Paula Werbosa w jego pracy doktorskiej, natomiast prawdziwym przełomem było rozwinięcie jej 1986 roku przez Davida E. Rumelharta, Geoffreya E. Hintora oraz Ronalda J. Williamsa. Ci trzej panowie odkryli, jak zastosować metodę Werbosa do uczenia sieci wielowarstwowych. Metoda ta nazwana została algorytmem wstecznej propagacji błędów.
Pytanie brzmi – dlaczego SI zaczęła być tak bardzo na czasie dopiero stosunkowo niedawno? Przecież już w 1986 roku mieliśmy odpowiednie narzędzia, a przynajmniej tak się może wydawać. Tymczasem sprawa jest znacznie bardziej skomplikowana; sytuację możemy porównać do patrzenia na odległy szczyt, ale bez możliwości zdobycia go. Wiemy, że tam jest, znamy ukształtowanie terenu i warunki na nim panujące, ale nie mamy odpowiednich do zdobycia go narzędzi. Nie mamy zasobów.


W przypadku sztucznych sieci neuronowych zasobami są moc obliczeniowa oraz dane. Moc obliczeniowa to kwestia oczywista – niemalże co roku zwiększamy nasze możliwości, jeśli chodzi o szybkość wykonywania obliczeń. Ba! Zaczynają nawet powstawać procesory dedykowane AI, które sprzętowo optymalizują wykonywane przez sztuczne sieci neuronowe operacje. Istotniejszy jest jednak zasób drugi, czyli dane. Na nic nam najwydajniejszy sprzęt i najdokładniejszy algorytm uczenia, jeśli nie mamy informacji, na podstawie których można się uczyć. Tutaj pojawia się rozwój pojemności pamięci, szybkości transferów czy wreszcie słynne Big Data; im więcej danych, tym większe pole do popisu dla sztucznej inteligencji.
Nie bez znaczenia jest także fakt, że tematem zainteresowały się wielkie koncerny. W 1986 roku sztuczna inteligencja była badana na uniwersytetach, natomiast nie znajdywała zastosowania w projektach komercyjnych. Nie tak, jak teraz. Współcześnie SI wpycha się dosłownie wszędzie, gdzie można coś zoptymalizować, zautomatyzować, prognozować czy rozpoznawać. Przykład? Mechanizm klasyfikowania poczty w Gmailu wykorzystuje SI; to, że nasze wiadomości automatycznie są tagowane „oferta”, „powiadomienie” czy „zakupy”, albo, że wiadomość z potwierdzeniem kupna biletu lotniczego powoduje wrzucenie do naszego kalendarza daty wylotu, to wszystko zasługa jakiejś odpowiednio nauczonej struktury neuronowej. Struktury nauczonej, jak podejrzewam, naszymi danymi. Bez zainteresowania gigantów pokroju Google’a sztuczne sieci neuronowe (jak i cała sztuczna inteligencja) nie rozwinęłaby się w tak zastraszającym tempie.


Po co nam sztuczne sieci neuronowe?
Na sam koniec zostawiłem krótkie przedstawienie współczesnych zastosowań tej dziedziny informatyki. Nie jest to spis w żadnym wypadku kompletny, bo lista zadań, do których SI pod postacią sztucznej sieci neuronowej może być wykorzystana, jest naprawdę konkretna.
Sztuczne sieci neuronowe można wykorzystywać do rozpoznawania rzeczy najróżniejszych, począwszy od pisma odręcznego, poprzez twarz, na nowotworach skóry skończywszy. Zdolność opisywanych struktur do generalizowania i uogólniania wiedzy jest nieoceniona. Wyobraźcie sobie, że aby nauczyć sieć rozpoznawania jakiejkolwiek twarzy, wystarczy jej przedstawić pewną liczbę dowolnych, losowych twarzy; prawidłowo nauczona sieć będzie w stanie rozpoznać twarz każdego innego człowieka. Oczywiście bardzo tutaj upraszczam sytuację, ale mniej więcej tak to wygląda.
Inną cechą, o której wspomniałem przy okazji opisu uczenia nienadzorowanego, jest zdolność do analizowania danych, kojarzenia ich i wnioskowania na ich podstawie. Wyobraźmy sobie, że mamy ogromny zbiór danych opisujących historię różnych procesów zachodzących w przedsiębiorstwie; potrzebujemy wyodrębnić z nich jak najwięcej zależności, ale nie mamy ochoty przeglądać tego wszystkiego ręcznie. Co robimy? Wrzucamy to wszystko w odpowiedniego typu sieć neuronową. Uzyskane wyniki znacznie pomogą nam w interpretacji danych; być może wykażą przyczynowość, być może pozwolą ustalić wyniki niepowodzeń, a być może zawczasu ostrzegą nas przed groźnymi konsekwencjami. Oczywiście analiza może być przeprowadzona za pomocą typowych algorytmów, ale, jak wspominałem w poprzednich odcinkach, typowe algorytmy trzeba programować pod konkretny problem, co w takich przypadkach nie jest zbyt efektywne.
Oprócz tego sztuczne sieci neuronowe zastosowanie znajdują w typowo technicznych zagadnieniach. Pozwalają prognozować i przewidywać, na przykład kursy akcji na giełdzie. Wykorzystywane są do optymalizacji i rozwiązywania zadań skomplikowanych obliczeniowo, a to dzięki współbieżnym obliczeniom wykonywanym przez wiele pracujących równocześnie elementów sieci. Niektóre zastosowania przewidują także wykorzystanie sztucznych sieci neuronowych do filtrowania sygnałów, na przykład do eliminacji szumów informacyjnych czy odrzucania nieistotnych faktów. Wreszcie sieci neuronowe można nauczyć… grać w gry. Zobaczcie ten filmik:

I tym samym dotarliśmy do końca tego odcinka. Jeśli kogoś zainteresowałem tematem tej konkretnej techniki sztucznej inteligencji, zachęcam do poszukiwania informacji na własną rękę, nie tylko w sieci, ale także w literaturze. Niektóre z faktów potrafią być naprawdę zaskakujące, a przecież mówimy o czymś, co zaczyna pojawiać się w dosłownie każdym aspekcie naszego życia. I tym miłym akcentem kończę dzisiejszy materiał. Do następnego!
źródło: Leszek Rutkowski Metody i techniki sztucznej inteligencji, Ryszard Tadeusiewicz Sieci Neuronowe (pdf dostępny tutaj), towardsdatascience, towardsdatascience
_
#MiniSI to cykl poświęcony zagadnieniu sztucznej inteligencji, w którym, bazując głównie na literaturze, staram się rozprawić z zagmatwaniem, poplątaniem, niejasnościami i różnorakimi mitami jej dotyczącymi.