Efekty wielu wysiłków Google, które zmierzają w kierunku ulepszania technologii uczenia maszynowego, są później publicznie udostępniane dla programistów. Dzięki temu najnowsze osiągnięcia technologicznego giganta mogą być wykorzystywane również przez innych. Tak jest na przykład z elementem oprogramowania, odpowiadającym za bardzo dobry tryb portretowy w smartfonie Pixel 2.
Model uczenia maszynowego, używany przez Google, przypisuje swego rodzaju etykiety do każdego piksela na przechwyconym obrazie. Taka kategoryzacja pozwala sklasyfikować grupy pikseli, które przybierając różne kształty, mogą być określane jako jakiś przedmiot, element tła, zwierzę czy człowiek. Odpowiednia klasyfikacja obiektów umożliwia precyzyjne „odcinanie” rzeczy znajdujących się na pierwszym planie w trybie portretowym. Dlatego efekt głębi ostrości uzyskiwany jest tylko z jednej soczewki aparatu i nie musi być wspierany przez drugą.

Tryb portretowy jest nieco bardziej wymagający niż funkcja rozpoznawania obiektów. Oprogramowanie musi dokładnie określić, gdzie „kończy się” człowiek, a gdzie „zaczyna się” tło, by precyzyjnie dobrać kontury postaci, poza którymi obraz zostanie rozmazany.
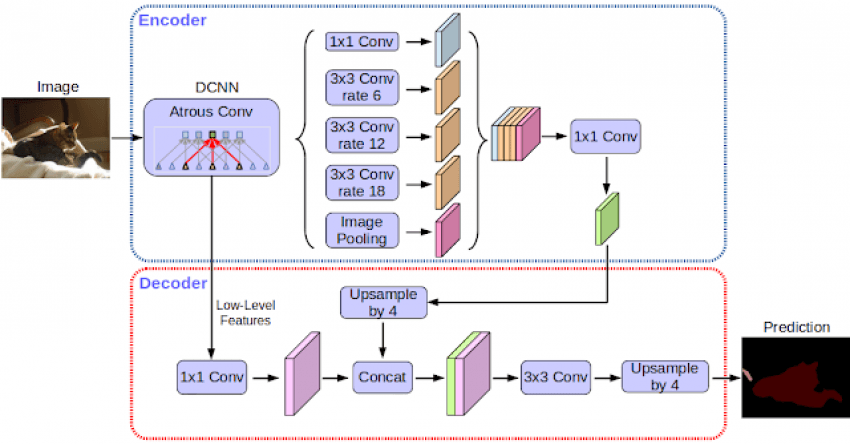
Jest to możliwe dzięki specjalnemu dekoderowi obrazu, który nazwano DeepLab-v3. Ten semantyczny model segmentacji obrazu używany jest w aparatach Google Pixel 2 i Pixel 2 XL. W wersji TensorFlow dodano do niego również moduł uczący się i kod umożliwiający ocenę dokładności działań.
Google zauważa, że obecnie rozpoznawanie obrazów osiągnęło poziom jeszcze pięć lat temu dla nas niedostępny – a to wszystko dzięki postępom w zakresie sprzętu, metod i zaplecza danych.
„Mamy nadzieję, że publiczne udostępnienie naszego systemu ułatwi innym środowiskom akademickim i przemysłowym odtworzenie, i dalsze doskonalenie najnowocześniejszych rozwiązań, szkolenie maszyn na nowych zbiorach danych oraz rozwój aplikacji, bazujących na tej technologii.” – czytamy na blogu Google.
https://www.tabletowo.pl/2018/02/23/recenzja-test-google-pixel-2-xl/
źródło: Google przez 9to5google